Latence Invisible : La Clé de la Victoire en IA
Imaginez un instant : vous parlez à un assistant vocal ultra-intelligent qui comprend vos nuances, anticipe vos besoins… mais qui met une seconde entière avant de répondre. Cette petite attente transforme l’expérience magique en frustration palpable. Et si ce détail apparemment anodin – la fameuse latence – devenait le véritable juge de paix entre les vainqueurs et les vaincus de la prochaine décennie en intelligence artificielle ?
Quand l’invisible devient décisif
Nous vivons dans une ère où l’instantanéité est devenue la norme. Une page web qui met plus de trois secondes à charger est considérée comme inutilisable. Une vidéo qui bufferise nous fait zapper immédiatement. Pourtant, quand il s’agit d’interagir avec l’intelligence artificielle la plus avancée du moment, nous acceptons encore assez facilement des délais de plusieurs centaines de millisecondes. Cette tolérance touche pourtant à sa fin.
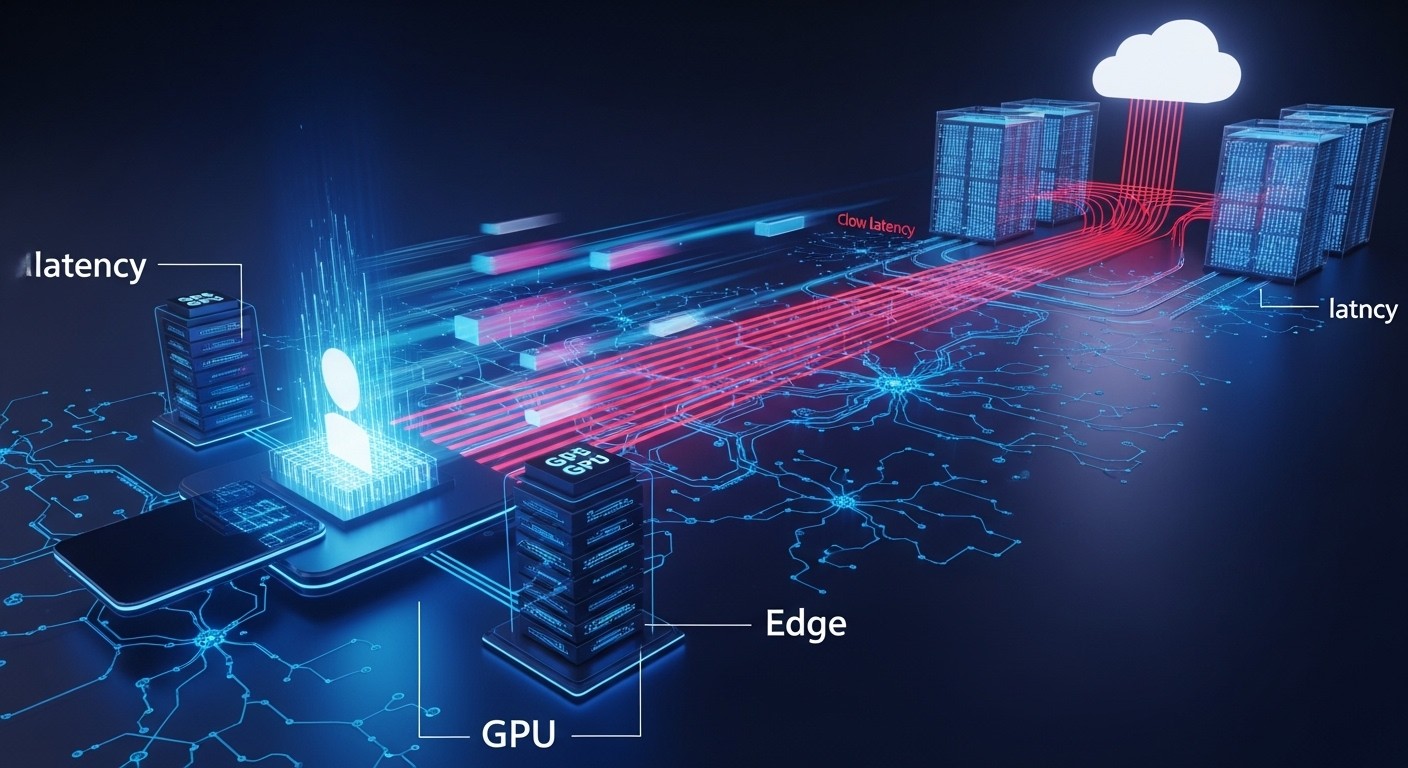
Les applications qui émergent aujourd’hui – agents vocaux conversationnels, robots industriels collaboratifs, véhicules autonomes, détection de fraude en temps réel, réalité augmentée immersive – ne pardonnent plus le moindre retard. Chaque milliseconde compte. Et contrairement à ce que beaucoup imaginent, ce n’est pas seulement la puissance brute des processeurs qui fait la différence : c’est surtout la distance physique entre l’utilisateur et le GPU qui exécute l’inférence.
Le fantôme qui hante l’IA moderne : la latence réseau
L’inférence IA actuelle s’effectue majoritairement dans d’immenses data centers centralisés, souvent situés à des centaines, voire des milliers de kilomètres de l’utilisateur final. Le signal doit donc faire un aller-retour complet : du smartphone ou de l’objet connecté jusqu’au serveur, puis retour avec la réponse générée. Dans les meilleures conditions, ce trajet prend déjà 80 à 150 ms. Ajoutez les traitements successifs (transcodage audio, tokenisation, génération, post-traitement) et vous atteignez facilement 400 à 800 ms de latence totale pour une simple interaction vocale.
Pour un chatbot textuel, cela reste acceptable. Pour une conversation naturelle, c’est rédhibitoire. Des études en psychologie des interactions montrent qu’un délai supérieur à 200-250 ms commence à perturber le rythme humain naturel. Au-delà de 500 ms, la fluidité disparaît complètement et l’utilisateur perçoit l’IA comme « lente » ou « artificielle ».
« Les utilisateurs ne remarquent pas la latence quand elle est faible… mais ils la ressentent immédiatement quand elle dépasse leur seuil de tolérance. »
– Observation largement partagée par les designers d’expériences conversationnelles
Pourquoi les CDN classiques ne suffisent plus
Depuis plus de vingt-cinq ans, les réseaux de distribution de contenu (Content Delivery Networks) ont résolu le problème de la latence pour les contenus statiques ou faiblement dynamiques. Mais l’IA générative change radicalement la donne : chaque requête produit une réponse unique, calculée à la volée. Impossible de pré-calculer ou de mettre en cache la quasi-totalité des outputs.
Le défi n’est donc plus seulement de distribuer des octets : il s’agit de distribuer du calcul GPU à l’échelle planétaire tout en maintenant une cohérence, une sécurité et une scalabilité acceptables. C’est un problème d’un ordre de complexité bien supérieur.
Les cas d’usage qui ne pardonnent rien
Voici quelques domaines où la latence devient un facteur limitant critique :
- Agents vocaux conversationnels en temps réel (call centers IA, compagnons virtuels)
- Robotique collaborative et cobots en usine
- Véhicules autonomes et prise de décision en périphérie
- Réalité augmentée / réalité mixte à faible latence (casques AR professionnels)
- Détection et réaction à la fraude bancaire en moins de 100 ms
- Jeux vidéo avec IA adversariale ultra-réactive
Dans tous ces cas, centraliser l’inférence dans quelques hyperscalers crée un goulot d’étranglement physique insurmontable sans architecture fondamentalement distribuée.
L’émergence d’un nouveau paradigme : l’edge inference
La réponse logique ressemble étrangement à ce qui s’est passé avec le web statique : rapprocher le calcul là où se trouvent les utilisateurs. Des plateformes spécialisées commencent à déployer des flottes de nœuds GPU à la périphérie des réseaux, dans des points de présence (PoP) proches des grandes populations.
En réduisant la distance physique, on divise souvent par 3 à 5 le temps de trajet aller-retour. Des latences réseau de 15 à 35 ms deviennent alors atteignables dans de nombreuses régions du monde, même densément peuplées. Combiné aux progrès fulgurants des puces d’inférence et des techniques de quantification, cela permet d’atteindre des expériences véritablement conversationnelles.
PolarGrid ou la naissance d’un CDN pour l’IA
Parmi les acteurs qui tentent de réinventer la distribution d’inférence IA, une jeune pousse canadienne se distingue particulièrement : PolarGrid. Cette société construit ni plus ni moins qu’un réseau mondial dédié à l’inférence IA en temps réel, avec des nœuds GPU déployés à la périphérie.
Leur promesse est simple mais ambitieuse : permettre à n’importe quel développeur de déployer un modèle en quelques minutes sur une infrastructure distribuée, sans avoir à gérer la complexité des multi-régions cloud classiques. Le routage intelligent choisit automatiquement le meilleur nœud en fonction de la latence, de la charge, du coût et de la localisation des données.
Ce type d’approche pourrait bien devenir l’équivalent moderne d’Akamai ou Cloudflare, mais pour le calcul IA plutôt que pour le contenu statique. Les premiers retours terrain montrent des gains de latence de 60 à 80 % sur des workloads conversationnels, ce qui change radicalement le ressenti utilisateur.
Vers une IA qui disparaît… parce qu’elle devient instantanée
L’histoire du numérique nous enseigne une leçon claire : les technologies qui réussissent vraiment sont celles qui deviennent invisibles. Le Wi-Fi, le cloud, les écrans tactiles… nous ne les remarquons plus parce qu’ils fonctionnent parfaitement. L’IA suivra le même chemin.
Mais pour disparaître dans la vie quotidienne, elle doit d’abord cesser de nous faire attendre. La bataille pour la suprématie en intelligence artificielle ne se jouera peut-être pas uniquement sur la taille des modèles ou sur la quantité de données d’entraînement. Elle pourrait bien se décider sur un paramètre bien plus prosaïque : le nombre de millisecondes qui séparent la pensée de l’utilisateur de la réponse de la machine.
Dans cette course invisible, les entreprises qui sauront rapprocher intelligemment le calcul des utilisateurs – sans sacrifier performance, sécurité et coût – auront un avantage déterminant. Les autres risquent de se retrouver coincées avec une IA puissante… mais frustrante.
Et vous, avez-vous déjà ressenti cette micro-seconde de trop qui transforme une interaction prometteuse en moment d’agacement ?
La prochaine révolution IA ne viendra peut-être pas d’un modèle 10 fois plus gros… mais d’une infrastructure 10 fois plus proche.











